La API JDBC es una API de Java que puede acceder a cualquier tipo de datos almacenados en una base de datos relacional. Para poder hacer uso de las clase de JDBC es necesario importar el paquete java.sql, para lo cual habrá que introducir en el código el import correspondiente:
import java.sql.*;
JDBC permite escribir aplicaciones Java que realicen cualquiera de estas tres actividades de programación:
- Conectar a un origen de datos, como puede ser una base de datos.
- Enviar consultas y sentencias de actualización a una base de datos.
- Obtener y procesar los resultados recibidos de la base de datos como respuesta a una consulta.
El siguiente fragmento de código puede servir como un ejemplo sencillo de estos tres pasos:
Connection con = DriverManager.getConnection("jdbc:miDriverBD:miBaseDatos", "miNombreUsuario", "miContraseña");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Tabla1");
while (rs.next()) {
int x = rs.getInt("a");
String s = rs.getString("b");
float f = rs.getFloat("c");
}
Este fragmento de código realiza las siguientes acciones:
- Crea un objeto DriverManager para realizar la conexión con un controlador (driver) específico del tipo de bases de datos correspondiente y accede a la base de datos mediante el nombre de usuario y contraseña especificados.
- Crea un objeto Statement que guarda la consulta a la base de datos en lenguaje SQL.
- Crea un objeto ResultSet que almacena los resultados de la consulta.
- Ejecuta un bucle while que recupera y muestra esos resultados.
El modelo de capas o niveles
El modelo más sencillo de funcionamiento de la API JDBC se basa en un esquema de dos capas o niveles. En este modelo, una aplicación o un applet Java se comunica directamente con el origen de los datos. Esto requiere un driver JDBC que pueda comunicarse con el tipo concreto de origen de datos al que se va a acceder.
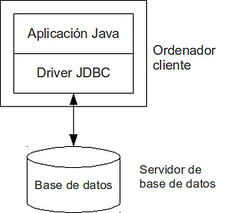
Las sentencias del usuario son enviados a la base de datos, y los resultados obtenidos son enviados de vuelta al usuario. La base de datos puede estar localizado en el mismo ordenador o bien en otra máquina a la que el usuario debe conectarse a través de la red. Ese último caso, es el correspondiente a una configuración cliente/servidor, en la que el ordenador del usuario es el cliente, y el ordenador en el que se encuentra la base de datos es el servidor. La red utilizada para conectarlos puede ser una intranet, o bien, a través de Internet.
Otro modelo de conexión es llamado de tres niveles, en el que las sentencias del usuario se envían a un nivel intermedio, que puede ser un servidor con el driver JDBC, el cual las reenviará a la base de datos, y los resultados obtenidos llevarán el mismo camino de vuelta.
ResultSets y cursores
Las filas que satisfacen las condiciones de una consulta reciben el nombre de conjunto de resultados (ResultSet). El número de filas retornadas en un ResultSet puede ser cero, una o varias. Podemos acceder a los datos contenidos en un ResultSet, obteniendo una fila cada vez, y un cursor nos proporciona el mecanismo para hacerlo. Podemos pensar que un cursor es como un puntero en un fichero, y ese puntero tiene la posibilidad de saber a qué fila se está accediendo. El cursor nos permite procesar cada fila de un ResultSet, desde el principio hasta el final. Las versiones más modernas de la API de JDBC proporcionan la capacidad de mover el cursor hacia delante y hacia atrás dentro de un ResultSet, así como colocarlo en una fila concreta.